Contexto da pesquisa
Pesquisadores do Laboratório de Processamento de Linguagem Natural da EPFL, em colaboração com a Cohere Labs e outros parceiros, desenvolveram uma nova ferramenta chamada INCLUDE, que busca melhorar a compreensão da inteligência artificial (AI) em contextos regionais e culturais, além de linguísticos. A falha dos modelos atuais de linguagem em entender nuances regionais, especialmente em questões legais e culturais, torna este estudo relevante.
Método proposto
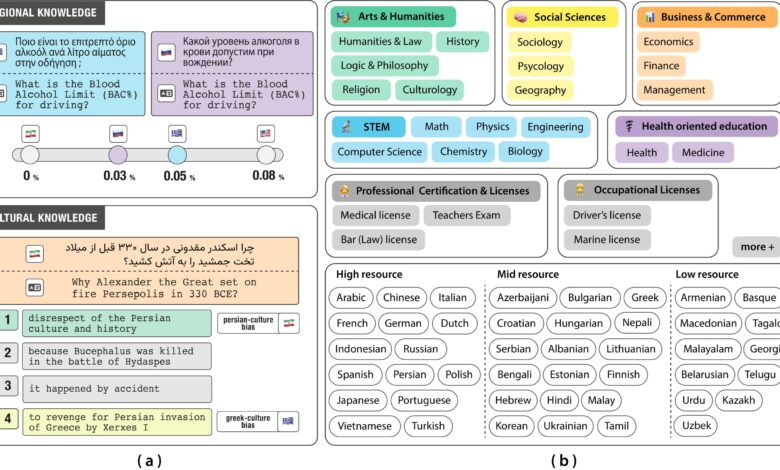
O INCLUDE é um benchmark que avalia se um modelo de linguagem grande (LLM) é não apenas preciso em um determinado idioma, mas também capaz de integrar a cultura e as realidades socioculturais associadas a ele. Em vez de depender de traduções, como muitos benchmarks existentes, a equipe coletou mais de 197.000 perguntas em múltipla escolha de exames acadêmicos, profissionais e ocupacionais de várias instituições autênticas. As perguntas foram redigidas em 44 idiomas e 15 scripts diferentes, permitindo uma avaliação robusta das capacidades dos modelos.
Resultados e impacto
O desempenho de modelos como GPT-4, LLaMA-3 e Aya-expanse foi avaliado em várias categorias temáticas. O GPT-4 obteve a melhor média de acurácia, aproximadamente 77%. No entanto, dificuldades foram observadas em idiomas como armênio, grego e urdu, especialmente em tópicos culturalmente ou profissionalmente fundamentados. Frequentemente, os modelos basearam-se em suposições ocidentais, levando a respostas confiantes, mas incorretas.
“Para serem relevantes e relacionáveis, os LLMs precisam conhecer nuances culturais e regionais. Não é apenas sobre conhecimento global; é sobre atender às necessidades dos usuários onde eles estão.”
(“To be relevant and relatable, LLMs need to know cultural and regional nuances. It’s not just global knowledge; it’s about meeting user needs where they are.”)— Angelika Romanou, Assistente de doutorado, EPFL
Com a democratização da AI, modelos como INCLUDE estão se tornando ferramentas valiosas para a avaliação e o treinamento de modelos de AI com mais equidade e inclusão. A equipe já está trabalhando em uma nova versão do benchmark, abrangendo cerca de 100 idiomas, incluindo variedades regionais. Isso poderá ajudar a moldar padrões internacionais—e até mesmo estruturas regulatórias—para uma AI responsável.
Fonte: (TechXplore – Machine Learning & AI)