São Paulo — InkDesign News — O uso de machine learning na modelagem preditiva ganhou destaque, especialmente com algoritmos como Random Forest e Bagging. Essas técnicas se mostram efetivas tanto para problemas de classificação quanto de regressão, mas enfrentam desafios como o sobreajuste.
Arquitetura de modelo
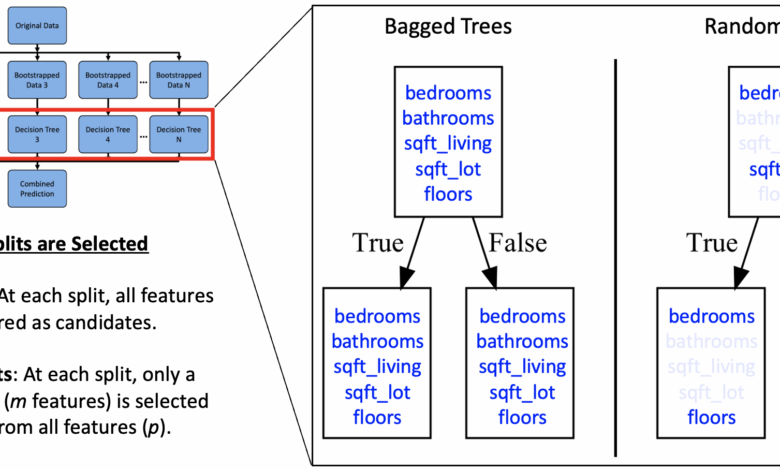
Os Random Forests são uma forma de agrupamento de árvores de decisão que melhora a predição ao combinar múltiplos modelos. Esta abordagem reduz a variabilidade que um único modelo poderia apresentar, utilizando a técnica conhecida como Bootstrap Aggregating (ou Bagging). Cada árvore no modelo é treinada em um conjunto diferente de dados amostrados, o que introduz diversidade e melhora a generalização.
Treinamento e otimização
“Treinar cada árvore em um conjunto bootstrapped introduz variação entre as árvores. Embora isso não elimine completamente a correlação, ajuda a reduzir o sobreajuste.”
(“Training each tree on a different bootstrapped sample introduces variation across trees. While this doesn’t fully eliminate correlation, it helps reduce overfitting.”)
— Michael Galarnyk, Engenheiro de Dados, Insight Media Group O processo de treinamento pode ser otimizado por meio de busca em grade para ajustar hiperparâmetros como o número de estimadores e a fração de características consideradas em cada divisão.
Resultados e métricas
Um fator crucial na utilização do Random Forest é a interpretação da importância das características. Métodos como Mean Decrease in Impurity e Permutation Importance são utilizados para entender quais variáveis têm maior impacto nas previsões. Os resultados muitas vezes indicam características geográficas e demográficas como influentes, como demonstrado no caso de vendas de imóveis na região de King County. “As características geográficas lat e long também se mostram úteis para visualizações.”
(“the geographic features lat and long are also useful for visualization.”)
— Michael Galarnyk, Engenheiro de Dados, Insight Media Group
Com o crescimento do uso de algoritmos de machine learning, o futuro aponta para ainda mais integrações entre o aprendizado preditivo e aplicações do mundo real. Pesquisas e modelagens contínuas serão essenciais para refinar esses modelos e explorar novas abordagens de otimização.
Fonte: (Towards Data Science – AI, ML & Deep Learning)

































